
Q.1 (a) Define the followings:
(1) System bus : System bus is a single computer bus that connects the major components of a computer system, combining the functions of a data bus to carry information, an address bus to determine where it should be sent or read from, and a control bus to determine its operation.
(2) Auxiliary memory : Auxiliary memory, also known as auxiliary storage, secondary storage, secondary memory or external memory, is a non-volatile memory (does not lose stored data when the device is powered down).
- The most common forms of auxiliary storage have been magnetic disks, magnetic tapes, and optical discs.
- Programs not currently needed in main memory are transferred into auxiliary memory to provide space in main memory for other programs that are currently in use.
- An Auxiliary memory is referred to as the lowest-cost, highest-space, and slowest-approach storage in a computer system.
The cache memory is used to store program data which is currently being executed in the CPU.
(c) What is process? Explain the process creation and termination.
A process is the instance of a computer program that is being executed by one or many threads. It contains the program code and its activity.
OR
A Process is something that is currently under execution. So, an active program can be called a Process.
For example, when you want to search something on web then you start a browser. So, this can be process.
The process creation and termination :
1. Process creation:
1. When a new process is created, the operating system assigns a unique Process Identifier (PID) to it and inserts a new entry in the primary process table.
2. Then required memory space for all the elements of the process such as program, data, and stack is allocated including space for its Process Control Block (PCB).
3. Next, the various values in PCB are initialized such as,
- The process identification part is filled with PID assigned to it in step (1) and also its parent’s PID.
- The processor register values are mostly filled with zeroes, except for the stack pointer and program counter. The stack pointer is filled with the address of the stack-allocated to it in step (ii) and the program counter is filled with the address of its program entry point.
- The process state information would be set to ‘New’.
- Priority would be lowest by default, but the user can specify any priority during creation.
4. Then the operating system will link this process to the scheduling queue and the process state would be changed from ‘New’ to ‘Ready’. Now the process is competing for the CPU.
5. Additionally, the operating system will create some other data structures such as log files or accounting files to keep track of processes activity.
2. Process Deletion:
Processes are terminated by themselves when they finish executing their last statement, then operating system USES exit( ) system call to delete its context. Then all the resources held by that process like physical and virtual memory, 10 buffers, open files, etc., are taken back by the operating system. A process P can be terminated either by the operating system or by the parent process of P.
A parent may terminate a process due to one of the following reasons:
- When task given to the child is not required now.
- When the child has taken more resources than its limit.
- The parent of the process is exciting, as a result, all its children are deleted. This is called cascaded termination.
| User level thread | Kernel level thread |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
all at time 0. Calculate the average turnaround time and maximum waiting time for per- emptive scheduling algorithm.

a) FCFS scheduling:
Here the processes are scheduled as per the order in which they arrive.
Gantt chart:

Waiting time for P1=0
Waiting time for P2=10
Waiting time for P3=11
Waiting time for P4=13
Waiting time for P5=14
Average waiting time
Average execution time
Average turn-around time = Average waiting time + Average execution time = 9.6 + 3.8 = 13.4
b) SJF non-preemptive scheduling:
Here the processes are scheduled as per their burst time with the least timed-process being given the maximum priority.

Waiting time for P1=9
Waiting time for P2=0
Waiting time for P3=2
Waiting time for P4=1
Waiting time for P5=4
Average waiting time
Average execution time
Average turn-around time= Average waiting time + Average execution time = 3.2 + 3.8 = 7
c) Priority scheduling :
Here the scheduling happens on the basis of priority number assigned to each process. (Here we would be considering Priority=1 as highest priority)

Waiting time for P1=6
Waiting time for P2=0
Waiting time for P3=16
Waiting time for P4=18
Waiting time for P5=1
Average waiting time
Average execution time
Average turn-around time= Average waiting time + Average execution time = 8.2 + 3.8 = 12
d) Round Robin scheduling:
Here every process executes in the FCFS for the given time quantum. This is a pre-emptive method of scheduling. Here time quantum =1

Waiting time for
Waiting time for P2=1
Waiting time for
Waiting time for P4=3
Waiting time for
Average waiting time
Average execution time
Average turn-around time= Average waiting time + Average execution time = 5.4 + 3.8 = 9.2
- Shortest remaining time (SRT) is the preemptive version of the SJN algorithm.
- The processor is allocated to the job closest to completion but it can be preempted by a newer ready job with shorter time to completion.
- Impossible to implement in interactive systems where required CPU time is not known.
- It is often used in batch environments where short jobs need to give preference.
Round Robin Scheduling
- Round Robin is the preemptive process scheduling algorithm.
- Each process is provided a fix time to execute, it is called a quantum.
- Once a process is executed for a given time period, it is preempted and other process executes for a given time period.
- Context switching is used to save states of preempted processes.
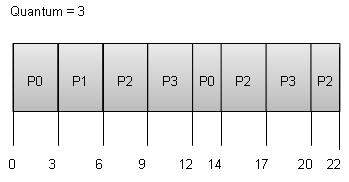
Wait time of each process is as follows −
| Process | Wait Time : Service Time - Arrival Time |
|---|---|
| P0 | (0 - 0) + (12 - 3) = 9 |
| P1 | (3 - 1) = 2 |
| P2 | (6 - 2) + (14 - 9) + (20 - 17) = 12 |
| P3 | (9 - 3) + (17 - 12) = 11 |
Average Wait Time: (9+2+12+11) / 4 = 8.5
Q.3 (a) What is meant priority inversion?
Priority inversion is a bug that occurs when a high priority task is indirectly preempted by a low priority task. For example, the low priority task holds a mutex that the high priority task must wait for to continue executing
(b) What is the criterion used to select the time quantum in case of round-robin scheduling algorithm? Explain it with a suitable example.
Round Robin is the preemptive process scheduling algorithm. Each process is provided a fix time to execute, it is called a quantum. Once a process is executed for a given time period, it is preempted and other process executes for a given time period. Context switching is used to save states of preempted processes.
Consider this following three processes

Step 1)


Step 2) At time =2, P1 is added to the end of the Queue and P2 starts executing

Step 3) At time=4 , P2 is preempted and add at the end of the queue. P3 starts executing.

Step 4) At time=6 , P3 is preempted and add at the end of the queue. P1 starts executing.

Step 5) At time=8 , P1 has a burst time of 4. It has completed execution. P2 starts execution

Step 6) P2 has a burst time of 3. It has already executed for 2 interval. At time=9, P2 completes execution. Then, P3 starts execution till it completes.

Step 7) Let’s calculate the average waiting time for above example.
Wait time
P1= 0+ 4= 4
P2= 2+4= 6
P3= 4+3= 7(c) What is Semaphore? Give the implementation of Bounded Buffer Producer Consumer Problem using Semaphore
Semaphores are integer variables that are used to solve the critical section problem by using two atomic operations, wait and signal that are used for process synchronization.
To solve the problem occurred of race condition, we use Binary Semaphore and Counting Semaphore
Binary Semaphore: In Binary Semaphore, only two processes can compete to enter into its CRITICAL SECTION at any point in time, apart from this the condition of mutual exclusion is also preserved.
Counting Semaphore: In counting semaphore, more than two processes can compete to enter into its CRITICAL SECTION at any point of time apart from this the condition of mutual exclusion is also preserved.
The four necessary conditions for a deadlock to arise are as follows.
- Mutual Exclusion: Only one process can use a resource at any given time i.e. the resources are non-sharable.
- Hold and wait: A process is holding at least one resource at a time and is waiting to acquire other resources held by some other process.
- No preemption: The resource can be released by a process voluntarily i.e. after execution of the process.
- Circular Wait: A set of processes are waiting for each other in a circular fashion. For example, lets say there are a set of processes {,,,} such that depends on , depends on , depends on and depends on . This creates a circular relation between all these processes and they have to wait forever to be executed.
The criteria include the following:
- CPU utilisation –
The main objective of any CPU scheduling algorithm is to keep the CPU as busy as possible. Theoretically, CPU utilisation can range from 0 to 100 but in a real-time system, it varies from 40 to 90 percent depending on the load upon the system.
- Throughput –
A measure of the work done by the CPU is the number of processes being executed and completed per unit of time. This is called throughput. The throughput may vary depending upon the length or duration of the processes.
- Turnaround time –
For a particular process, an important criterion is how long it takes to execute that process. The time elapsed from the time of submission of a process to the time of completion is known as the turnaround time. Turn-around time is the sum of times spent waiting to get into memory, waiting in the ready queue, executing in CPU, and waiting for I/O. The formula to calculate Turn Around Time = Compilation Time – Arrival Time
- Waiting time –
A scheduling algorithm does not affect the time required to complete the process once it starts execution. It only affects the waiting time of a process i.e. time spent by a process waiting in the ready queue. The formula for calculating Waiting Time = Turnaround Time – Burst Time.
- Response time –
In an interactive system, turn-around time is not the best criteria. A process may produce some output fairly early and continue computing new results while previous results are being output to the user. Thus another criteria is the time taken from submission of the process of request until the first response is produced. This measure is called response time. The formula to calculate Response Time = CPU Allocation Time(when the CPU was allocated for the first) – Arrival Time
Producer Consumer Problem using Monitor.
Monitors make solving the producer-consumer a little easier. Mutual exclusion is achieved by placing the critical section of a program inside a monitor. In the code below, the critical sections of the producer and consumer are inside the monitor ProducerConsumer. Once inside the monitor, a process is blocked by the Wait and Signal primitives if it cannot continue.
condition full, empty;
int count;
procedure enter();
{
if (count == N) wait(full); // if buffer is full, block
put_item(widget); // put item in buffer
count = count + 1; // increment count of full slots
if (count == 1) signal(empty); // if buffer was empty, wake consumer
}
procedure remove();
{
if (count == 0) wait(empty); // if buffer is empty, block
remove_item(widget); // remove item from buffer
count = count - 1; // decrement count of full slots
if (count == N-1) signal(full); // if buffer was full, wake producer
}
count = 0;
end monitor;
Producer();
{
while (TRUE)
{
make_item(widget); // make a new item
ProducerConsumer.enter; // call enter function in monitor
}
}
Consumer();
{
while (TRUE)
{
ProducerConsumer.remove; // call remove function in monitor
consume_item; // consume an item
}
}
Q.4 (a) What is resource allocation graph?
- This technique keeps the track of all the free frames.
- The Frame has the same size as that of a Page. A frame is basically a place where a (logical) page can be (physically) placed.


As shown on the above image
Memory blocks available are : {100, 50, 30, 120, 35}
Process P1, size: 20
- OS Searches memory from sequentially from starting
- Block 1 fits, P1 gets assigned to block 1
Process P2, size: 60
- OS Searches memory sequentially from block 1 again
- Block 1 is unavailable, Block 2 and 3 can’t fit
- Block 4 fits, p2 assigned to block 4
Process P3, size: 70
- OS Searches memory sequentially from block 1 again
- Block 1 is unavailable, Block 2, 3 can’t fit. Block 4 unavailable, Block 5 can’t fit
- P3 remains unallocated
Similarly, P4 is assigned to block 2


- Step 1: Input memory block with a size.
- Step 2: Input process with size.
- Step 3: Initialize by selecting each process to find the maximum block size that can be assigned to the current process.
- Step 4: If the condition does not fulfill, they leave the process.
- Step 5: If the condition is not fulfilled, then leave the process and check for the next process.
- Step 6: Stop.

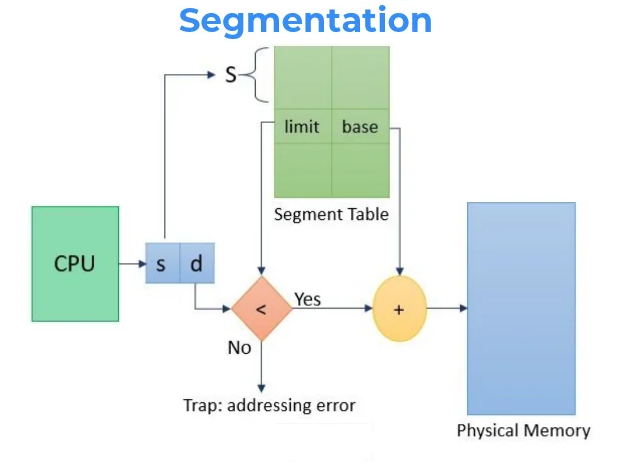
- Segment Number (s) – It is basically the total number of bits that are required to store any particular address of the segment in consideration
- Segment Offset (d) – Number of bits required for the size of the segment.
| S.NO | Internal fragmentation | External fragmentation |
|---|---|---|
| 1. | In internal fragmentation fixed-sized memory, blocks square measure appointed to process. | In external fragmentation, variable-sized memory blocks square measure appointed to the method. |
| 2. | Internal fragmentation happens when the method or process is smaller than the memory. | External fragmentation happens when the method or process is removed. |
| 3. | The solution of internal fragmentation is the best-fit block. | The solution to external fragmentation is compaction and paging. |
| 4. | Internal fragmentation occurs when memory is divided into fixed-sized partitions. | External fragmentation occurs when memory is divided into variable size partitions based on the size of processes. |
| 5. | The difference between memory allocated and required space or memory is called Internal fragmentation. | The unused spaces formed between non-contiguous memory fragments are too small to serve a new process, which is called External fragmentation. |
| 6. | Internal fragmentation occurs with paging and fixed partitioning. | External fragmentation occurs with segmentation and dynamic partitioning. |
| 7. | It occurs on the allocation of a process to a partition greater than the process’s requirement. The leftover space causes degradation system performance. | It occurs on the allocation of a process to a partition greater which is exactly the same memory space as it is required. |
| 8. | It occurs in worst fit memory allocation method. | It occurs in best fit and first fit memory allocation method. |
An access control list (ACL) contains rules that grant or deny access to certain digital environments.
Each system resource has a security attribute that identifies its access control list. The list includes an entry for every user who can access the system. The most common privileges for a file system ACL include the ability to read a file or all the files in a directory, to write to the file or files, and to execute the file if it is an executable file or program. ACLs are also built into network interfaces and operating systems (OSes), including Linux and Windows. On a computer network, access control lists are used to prohibit or allow certain types of traffic to the network. They commonly filter traffic based on its source and destination.
There are two types of ACLs:
- Filesystem ACLs━filter access to files and/or directories. Filesystem ACLs tell operating systems which users can access the system, and what privileges the users are allowed.
- Networking ACLs━filter access to the network. Networking ACLs tell routers and switches which type of traffic can access the network, and which activity is allowed.
Originally, ACLs were the only way to achieve firewall protection. Today, there are many types of firewalls and alternatives to ACLs. However, organizations continue to use ACLs in conjunction with technologies like virtual private networks (VPNs) that specify which traffic should be encrypted and transferred through a VPN tunnel.
Q.5 (a) Explain i/o buffering.
I/O buffering The process of temporarily storing data that is passing between a processor and a peripheral. The usual purpose is to smooth out the difference in rates at which the two devices can handle data.
Virtualization relies on software to simulate hardware functionality and create a virtual computer system. This enables IT organizations to run more than one virtual system – and multiple operating systems and applications – on a single server. The resulting benefits include economies of scale and greater efficiency.
1. Protection from system failures
No matter how careful you are with the technology you use, technology in general can sometimes be prone to system issues. Businesses can handle a few glitches, but if your developer is working on an important application that needs to be finished immediately, the last thing you need is a system crash.
One advantage of virtualization in cloud computing is the automatic backup that takes place across multiple devices. By storing all your backup data through virtualized cloud services or networks, you can easily access files from any device. This multi-layered access prevents you from losing any files, even if one system goes down for a time.
2. Hassle-free data transfers
Another benefit of virtualization in cloud computing is expedited data transfer. You can easily transfer data from physical storage to a virtual server, and vice versa. Virtualization in cloud computing can also handle long-distance data transfers. Administrators don’t have to waste time digging through hard drives to find data. Instead, dedicated server and cloud storage space allow you to easily locate required files and transfer them appropriately.
3. Firewall and security support
Security remains a central focus in the IT space. Through virtual firewalls, made possible through computer virtualization, you can restrict access to your data at much lower costs compared to traditional data protection methods. Virtualization earns you protection from many potential cybersecurity issues, through a virtual switch that protects your data and applications from harmful malware, viruses and other threats.
Firewall features for network virtualization allow you to create segments within the system. Server virtualization storage on cloud services will save you from the risks of lost or corruputed data. Cloud services are also encrypted with high-end protocols that protect your data from various other threats. When data security is on the line, virtualization offers premium-level protection without many of the associated firewall costs.
4. Smoother IT operations
Virtual networks help IT professionals improve efficiency in the workplace. These networks are easy to operate and faster to process, eliminating downtime and helping you save progress in real time. Before virtual networks were introduced in the digital world, technical workers could take days, sometimes weeks, to create and sufficiently support the same data across physical servers.
Apart from the operations, virtualization also helps IT support teams solve critical, sometimes nuanced technical problems in cloud computing environments. Because data is always available on a virtual server, technicians don’t have to waste time recovering files from crashed or corrupted devices.
5. Cost-effective strategies
Virtualization is a great way to reduce operational costs. With all the data stored on virtual servers or clouds, there’s hardly a need for physical systems or hardware, saving businesses a significant amount in waste, electricity and maintenance fees. In fact, 70% of senior executives support the integration of virtualization at some level across their organization, specifically for its time-saving properties. Virtualization also saves companies a significant amount of server space, which can then be utilized to further improve daily operations.
(c) Why is segmented paging important (as compared to a paging system)? What are
the different pieces of the virtual address in a segmented paging?
Advantages of Segmented Paging
The page table size is reduced as pages are present only for data of segments, hence reducing the memory requirements.
Gives a programmers view along with the advantages of paging.
Reduces external fragmentation in comparison with segmentation.
Since the entire segment need not be swapped out, the swapping out into virtual memory becomes easier .