Q.1 (a) Define the essential properties of the following types of operating systems:
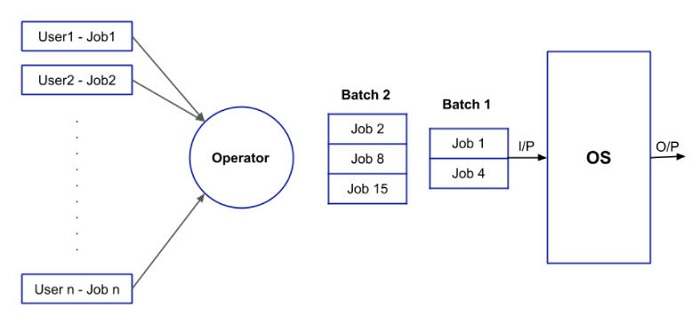
(1) Batch
The batch operating system grouped jobs that perform similar functions. These job groups are treated as a batch and executed simultaneously. A computer system with this operating system performs the following batch processing activities :
The steps to be followed by batch operating system are as follows −
Step 1 − Using punch cards the user prepares his job.
Step 2 − After that the user submits the job to the programmer.
Step 3 − The programmer collects the jobs from different users and sorts the jobs into batches with similar needs.
Step 4 − Finally, the programmer submits the batches to the processor one by one.
Step 5 − All the jobs of a single batch are executed together.
Advantages
The advantages of batch operating system are as follows −
The time taken by the system to execute all the programs will be reduced.
It can be shared between multiple users.
Disadvantages
The disadvantages of batch operating system are as follows −
Manual interrupts are required between two batches.
Priority of jobs is not set, they are executed sequentially.
It may lead to starvation.
The CPU utilization is low and it has to remain ideal for a long time because the time taken in loading and unloading of batches is very high as compared to execution time.
(2) Time-sharing
Time-sharing enables many people, located at various terminals, to use a particular computer system at the same time. Multitasking or Time-Sharing Systems is a logical extension of multi-programming. Processor’s time is shared among multiple users simultaneously is termed as time-sharing.
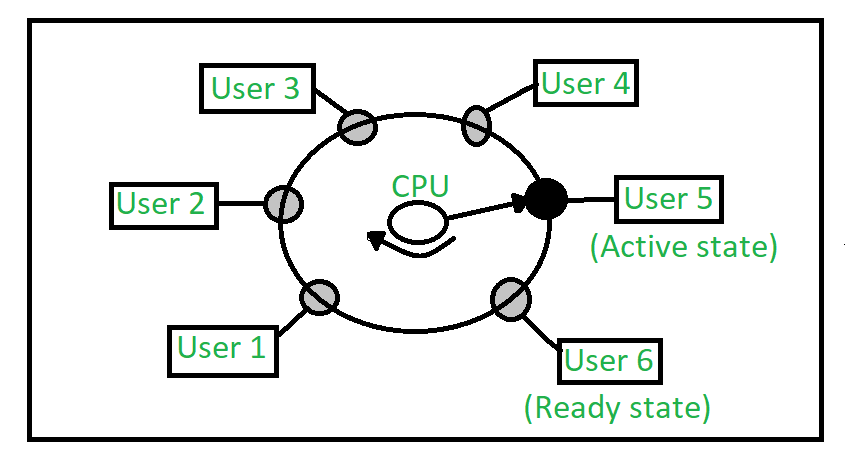
In above figure the user 5 is active state but user 1, user 2, user 3, and user 4 are in waiting state whereas user 6 is in ready state.
- Active State – The user’s program is under the control of CPU. Only one program is available in this state.
- Ready State – The user program is ready to execute but it is waiting for it’s turn to get the CPU.More than one user can be in ready state at a time.
- Waiting State – The user’s program is waiting for some input/output operation. More than one user can be in a waiting state at a time.
Requirements of Time Sharing Operating System : An alarm clock mechanism to send an interrupt signal to the CPU after every time slice. Memory Protection mechanism to prevent one job’s instructions and data from interfering with other jobs.
Advantages :
- Each task gets an equal opportunity.
- Less chances of duplication of software.
- CPU idle time can be reduced.
Disadvantages :
- Reliability problem.
- One must have to take of security and integrity of user programs and data.
- Data communication problem.
(3) Real-time
Real-time operating systems (RTOS) are used in environments where a large number of events, mostly external to the computer system, must be accepted and processed in a short time or within certain deadlines.This system is time-bound and has a fixed deadline.
Examples of the real-time operating systems: Airline traffic control systems, Command Control Systems, Airlines reservation system, Heart Pacemaker, Network Multimedia Systems, Robot etc.
The real-time operating systems can be of 3 types –
- Hard Real-Time operating system:
These operating systems guarantee that critical tasks be completed within a range of time.For example, a robot is hired to weld a car body. If the robot welds too early or too late, the car cannot be sold, so it is a hard real-time system that requires complete car welding by robot hardly on the time.
- Soft real-time operating system:
This operating system provides some relaxation in the time limit.For example – Multimedia systems, digital audio systems etc. Explicit, programmer-defined and controlled processes are encountered in real-time systems. A separate process is changed with handling a single external event. The process is activated upon occurrence of the related event signalled by an interrupt.
Multitasking operation is accomplished by scheduling processes for execution independently of each other. Each process is assigned a certain level of priority that corresponds to the relative importance of the event that it services. The processor is allocated to the highest priority processes. This type of schedule, called, priority-based preemptive scheduling is used by real-time systems.
- Firm Real-time Operating System:
RTOS of this type have to follow deadlines as well. In spite of its small impact, missing a deadline can have unintended consequences, including a reduction in the quality of the product. Example: Multimedia applications.
Advantages:
The advantages of real-time operating systems are as follows-
- Maximum consumption –
Maximum utilization of devices and systems. Thus more output from all the resources. - Task Shifting –
Time assigned for shifting tasks in these systems is very less. For example, in older systems, it takes about 10 microseconds. Shifting one task to another and in the latest systems, it takes 3 microseconds. - Focus On Application –
Focus on running applications and less importance to applications that are in the queue. - Real-Time Operating System In Embedded System –
Since the size of programs is small, RTOS can also be embedded systems like in transport and others. - Error Free –
These types of systems are error-free. - Memory Allocation –
Memory allocation is best managed in these types of systems.
Disadvantages:
The disadvantages of real-time operating systems are as follows-
- Limited Tasks –
Very few tasks run simultaneously, and their concentration is very less on few applications to avoid errors. - Use Heavy System Resources –
Sometimes the system resources are not so good and they are expensive as well. - Complex Algorithms –
The algorithms are very complex and difficult for the designer to write on. - Device Driver And Interrupt signals –
It needs specific device drivers and interrupts signals to respond earliest to interrupts. - Thread Priority –
It is not good to set thread priority as these systems are very less prone to switching tasks. - Minimum Switching – RTOS performs minimal task switching.
Q.1 (b) What are the advantages of multiprogramming?
Multiprogramming : Multiprogramming operating system allows to execute multiple processes by monitoring their process states and switching in between processes. It executes multiple programs to avoid CPU and memory underutilization. It is also called as Multiprogram Task System. It is faster in processing than Batch Processing system. Advantages of Multiprogramming :
- CPU never becomes idle
- Efficient resources utilization
- Response time is shorter
- Short time jobs completed faster than long time jobs
- Increased Throughput
A thread is a single sequential flow of execution of tasks of a process so it is also known as thread of execution or thread of control. There is a way of thread execution inside the process of any operating system. Apart from this, there can be more than one thread inside a process. Each thread of the same process makes use of a separate program counter and a stack of activation records and control blocks. Thread is often referred to as a lightweight process.
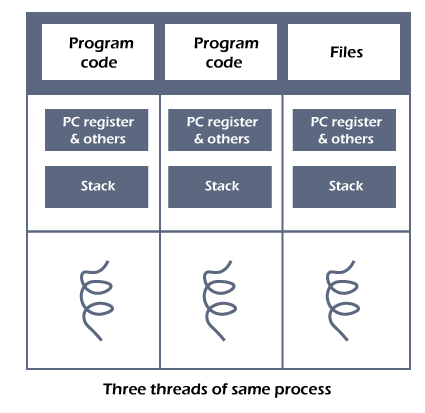
The process can be split down into so many threads. For example, in a browser, many tabs can be viewed as threads. MS Word uses many threads - formatting text from one thread, processing input from another thread, etc.
| User-level threads | Kernel-level threads |
|---|---|
|
|
|
|
|
|
|
|
In a multiprocessor environment, the kernel-level threads are better than user-level threads, because kernel-level threads can run on different processors simultaneously while user-level threads of a process will run on one processor only even if multiple processors are available.
Q.2 (a) What is Process? Give the difference between a process and a program.
Process : In the Operating System, a Process is something that is currently under execution. So, an active program can be called a Process. For example, when you want to search something on web then you start a browser. So, this can be process.
| Sr.No. | Program | Process |
|---|---|---|
| 1. | Program contains a set of instructions designed to complete a specific task. | Process is an instance of an executing program. |
| 2. | Program is a passive entity as it resides in the secondary memory. | Process is a active entity as it is created during execution and loaded into the main memory. |
| 3. | Program exists at a single place and continues to exist until it is deleted. | Process exists for a limited span of time as it gets terminated after the completion of task. |
| 4. | Program is a static entity. | Process is a dynamic entity. |
| 5. | Program does not have any resource requirement, it only requires memory space for storing the instructions. | Process has a high resource requirement, it needs resources like CPU, memory address, I/O during its lifetime. |
| 6. | Program does not have any control block. | Process has its own control block called Process Control Block. |
| 7. | Program has two logical components: code and data. | In addition to program data, a process also requires additional information required for the management and execution. |
| 8. | Program does not change itself. | Many processes may execute a single program. There program code may be the same but program data may be different. these are never same. |
Q.2 (b) What is Process State? Explain different states of a process with various queues generated at each stage.
The process executes when it changes the state. The state of a process is defined by the current activity of the process.
Each process may be in any one of the following states −
New − The process is being created.
Running − In this state the instructions are being executed.
Waiting − The process is in waiting state until an event occurs like I/O operation completion or receiving a signal.
Ready − The process is waiting to be assigned to a processor.
Terminated − the process has finished execution.
It is important to know that only one process can be running on any processor at any instant. Many processes may be ready and waiting.
Now let us see the state diagram of these process states −
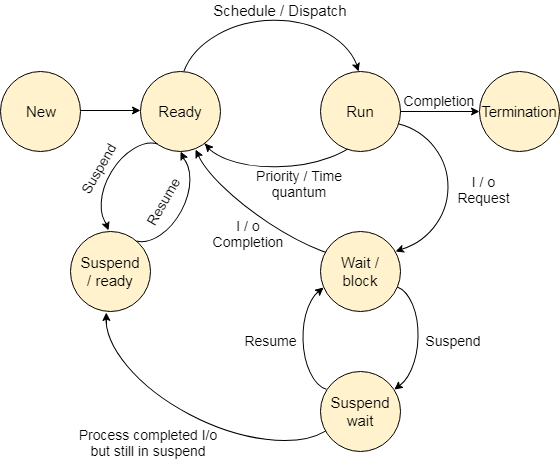
Explanation
Step 1 − Whenever a new process is created, it is admitted into ready state.
Step 2 − If no other process is present at running state, it is dispatched to running based on scheduler dispatcher.
Step 3 − If any higher priority process is ready, the uncompleted process will be sent to the waiting state from the running state.
Step 4 − Whenever I/O or event is completed the process will send back to ready state based on the interrupt signal given by the running state.
Step 5 − Whenever the execution of a process is completed in running state, it will exit to terminate state, which is the completion of process.
Q.2 (c) Write a bounded-buffer monitor in which the buffers (portions) are embedded within the monitor itself.
monitor bounded buffer {
int items[MAX ITEMS];
int numItems = 0;
condition full, empty;
void produce(int v)
{
while (numItems == MAX ITEMS) full.wait();
items[numItems++] = v;
empty.signal();
}
int consume()
{
int retVal;
while (numItems == 0) empty.wait();
retVal = items[--numItems];
full.signal();
return retVal;
}
}
OR Q.2 (c) What is Semaphore? Give the implementation of Readers-Writers Problem using Semaphore
A semaphore is a variable or abstract data type used to control access to a common resource by multiple threads and avoid critical section problems in a concurrent system such as a multitasking operating system.
The readers-writers problem is a classical problem of process synchronization, it relates to a data set such as a file that is shared between more than one process at a time. Among these various processes, some are Readers - which can only read the data set; they do not perform any updates, some are Writers - can both read and write in the data sets.The readers-writers problem is used to manage synchronization so that there are no problems with the object data. For example - If two readers access the object at the same time there is no problem. However if two writers or a reader and writer access the object at the same time, there may be problems.To solve this situation, a writer should get exclusive access to an object i.e. when a writer is accessing the object, no reader or writer may access it. However, multiple readers can access the object at the same time.
This can be implemented using semaphores. The codes for the reader and writer process in the reader-writer problem are given as follows −
Reader Process
The code that defines the reader process is given below −
wait (mutex);
rc ++;
if (rc == 1)
wait (wrt);
signal(mutex);
.
. READ THE OBJECT
.
wait(mutex);
rc --;
if (rc == 0)
signal (wrt);
signal(mutex);In the above code, mutex and wrt are semaphores that are initialized to 1. Also, rc is a variable that is initialized to 0. The mutex semaphore ensures mutual exclusion and wrt handles the writing mechanism and is common to the reader and writer process code.
The variable rc denotes the number of readers accessing the object. As soon as rc becomes 1, wait operation is used on wrt. This means that a writer cannot access the object anymore. After the read operation is done, rc is decremented. When re becomes 0, signal operation is used on wrt. So a writer can access the object now.
Writer Process
The code that defines the writer process is given below:
wait(wrt);
.
. WRITE INTO THE OBJECT
.
signal(wrt);If a writer wants to access the object, wait operation is performed on wrt. After that no other writer can access the object. When a writer is done writing into the object, signal operation is performed on wrt.
Q.3 (a) Define the difference between preemptive and non preemptive scheduling.
| Parameter | PREEMPTIVE SCHEDULING | NON-PREEMPTIVE SCHEDULING |
|---|---|---|
| Basic | In this resources(CPU Cycle) are allocated to a process for a limited time. | Once resources(CPU Cycle) are allocated to a process, the process holds it till it completes its burst time or switches to waiting state. |
| Interrupt | Process can be interrupted in between. | Process can not be interrupted until it terminates itself or its time is up. |
| Starvation | If a process having high priority frequently arrives in the ready queue, a low priority process may starve. | If a process with a long burst time is running CPU, then later coming process with less CPU burst time may starve. |
| Overhead | It has overheads of scheduling the processes. | It does not have overheads. |
| Flexibility | flexible | rigid |
| Cost | cost associated | no cost associated |
| CPU Utilization | In preemptive scheduling, CPU utilization is high. | It is low in non preemptive scheduling. |
| Waiting Time | Preemptive scheduling waiting time is less. | Non-preemptive scheduling waiting time is high. |
| Response Time | Preemptive scheduling response time is less. | Non-preemptive scheduling response time is high. |
| Examples | Examples of preemptive scheduling are Round Robin and Shortest Remaining Time First. | Examples of non-preemptive scheduling are First Come First Serve and Shortest Job First. |
Q.3 (c) What is deadlock? Explain deadlock prevention in detail.
We can prevent Deadlock by eliminating any of the above four conditions.
- Mutual Exclusion
- Hold and Wait
- No preemption
- Circular wait
Eliminate Mutual Exclusion
It is not possible to dis-satisfy the mutual exclusion because some resources, such as the tape drive and printer, are inherently non-shareable.
Eliminate Hold and wait
- Allocate all required resources to the process before the start of its execution, this way hold and wait condition is eliminated but it will lead to low device utilization. for example, if a process requires printer at a later time and we have allocated printer before the start of its execution printer will remain blocked till it has completed its execution.
- The process will make a new request for resources after releasing the current set of resources. This solution may lead to starvation.
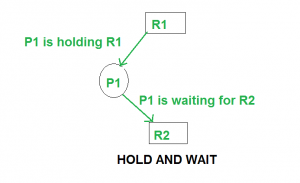
Eliminate No Preemption
Preempt resources from the process when resources required by other high priority processes.
Eliminate Circular Wait
Each resource will be assigned with a numerical number. A process can request the resources increasing/decreasing. order of numbering.
For Example, if P1 process is allocated R5 resources, now next time if P1 ask for R4, R3 lesser than R5 such request will not be granted, only request for resources more than R5 will be granted.
Q.3 (b) What are the Allocation Methods of a Disk Space?
- Contiguous Allocation
- Linked Allocation
- Indexed Allocation
1. Contiguous Allocation
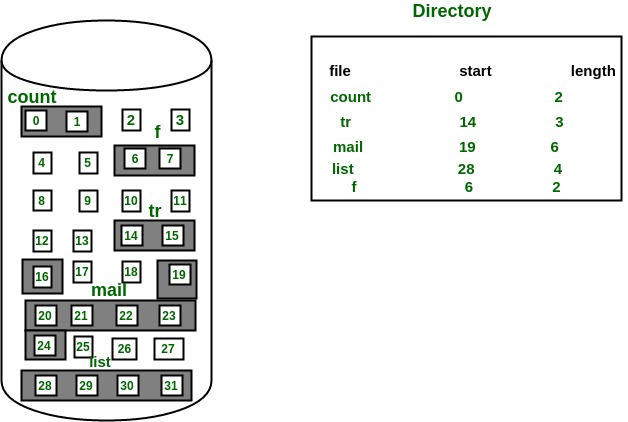
In this scheme, each file occupies a contiguous set of blocks on the disk. For example, if a file requires n blocks and is given a block b as the starting location, then the blocks assigned to the file will be: b, b+1, b+2,……b+n-1. This means that given the starting block address and the length of the file (in terms of blocks required), we can determine the blocks occupied by the file.
The directory entry for a file with contiguous allocation contains
- Address of starting block
- Length of the allocated portion.
The file ‘mail’ in the following figure starts from the block 19 with length = 6 blocks. Therefore, it occupies 19, 20, 21, 22, 23, 24 blocks.
Advantages:
- Both the Sequential and Direct Accesses are supported by this. For direct access, the address of the kth block of the file which starts at block b can easily be obtained as (b+k).
- This is extremely fast since the number of seeks are minimal because of contiguous allocation of file blocks.
Disadvantages:
- This method suffers from both internal and external fragmentation. This makes it inefficient in terms of memory utilization.
- Increasing file size is difficult because it depends on the availability of contiguous memory at a particular instance.
2. Linked List Allocation
In this scheme, each file is a linked list of disk blocks which need not be contiguous. The disk blocks can be scattered anywhere on the disk.
The directory entry contains a pointer to the starting and the ending file block. Each block contains a pointer to the next block occupied by the file.
The file ‘jeep’ in following image shows how the blocks are randomly distributed. The last block (25) contains -1 indicating a null pointer and does not point to any other block.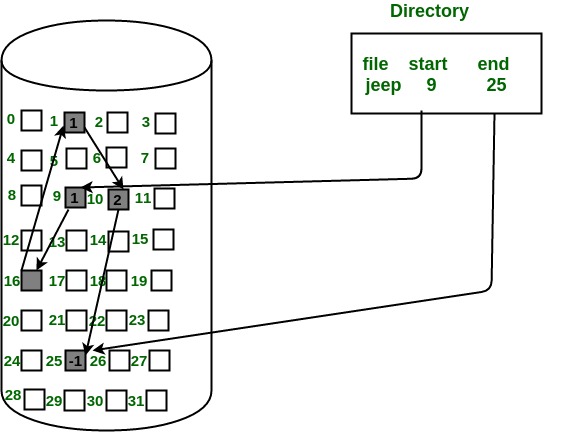
Advantages:
- This is very flexible in terms of file size. File size can be increased easily since the system does not have to look for a contiguous chunk of memory.
- This method does not suffer from external fragmentation. This makes it relatively better in terms of memory utilization.
Disadvantages:
- Because the file blocks are distributed randomly on the disk, a large number of seeks are needed to access every block individually. This makes linked allocation slower.
- It does not support random or direct access. We can not directly access the blocks of a file. A block k of a file can be accessed by traversing k blocks sequentially (sequential access ) from the starting block of the file via block pointers.
- Pointers required in the linked allocation incur some extra overhead.
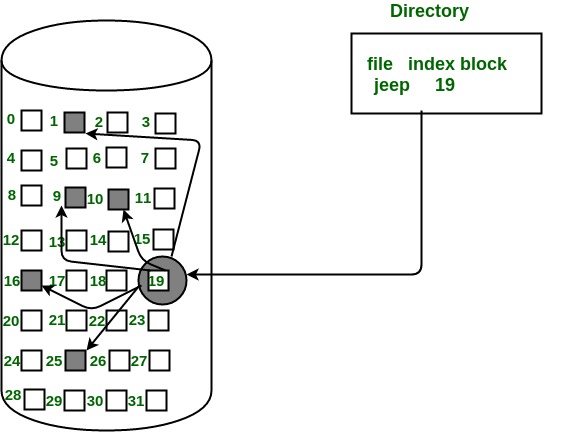
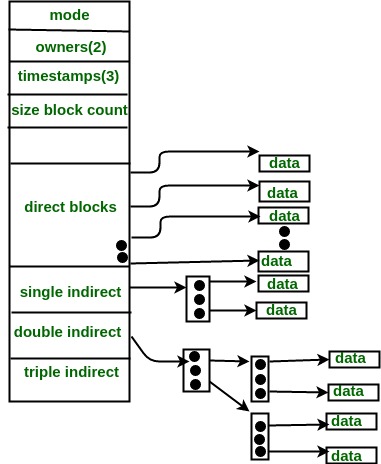
3. Indexed Allocation
In this scheme, a special block known as the Index block contains the pointers to all the blocks occupied by a file. Each file has its own index block. The ith entry in the index block contains the disk address of the ith file block. The directory entry contains the address of the index block as shown in the image:
Advantages:
- This supports direct access to the blocks occupied by the file and therefore provides fast access to the file blocks.
- It overcomes the problem of external fragmentation.
Disadvantages:
- The pointer overhead for indexed allocation is greater than linked allocation.
- For very small files, say files that expand only 2-3 blocks, the indexed allocation would keep one entire block (index block) for the pointers which is inefficient in terms of memory utilization. However, in linked allocation we lose the space of only 1 pointer per block.
For files that are very large, single index block may not be able to hold all the pointers.
Following mechanisms can be used to resolve this:
- Linked scheme: This scheme links two or more index blocks together for holding the pointers. Every index block would then contain a pointer or the address to the next index block.
- Multilevel index: In this policy, a first level index block is used to point to the second level index blocks which inturn points to the disk blocks occupied by the file. This can be extended to 3 or more levels depending on the maximum file size.
<segment-number,offset>
- Base: It is the base address of the segment
- Limit: It is the length of the segment.
1. Fixed Partitioning :
Multi-programming with fixed partitioning is a contiguous memory management technique in which the main memory is divided into fixed sized partitions which can be of equal or unequal size. Whenever we have to allocate a process memory then a free partition that is big enough to hold the process is found. Then the memory is allocated to the process.If there is no free space available then the process waits in the queue to be allocated memory. It is one of the most oldest memory management technique which is easy to implement.

2. Variable Partitioning :
Multi-programming with variable partitioning is a contiguous memory management technique in which the main memory is not divided into partitions and the process is allocated a chunk of free memory that is big enough for it to fit. The space which is left is considered as the free space which can be further used by other processes. It also provides the concept of compaction. In compaction the spaces that are free and the spaces which not allocated to the process are combined and single large memory space is made.

Difference between Fixed Partitioning and Variable Partitioning :
| S.NO. | Fixed partitioning | Variable partitioning |
|---|---|---|
| 1. | In multi-programming with fixed partitioning the main memory is divided into fixed sized partitions. | In multi-programming with variable partitioning the main memory is not divided into fixed sized partitions. |
| 2. | Only one process can be placed in a partition. | In variable partitioning, the process is allocated a chunk of free memory. |
| 3. | It does not utilize the main memory effectively. | It utilizes the main memory effectively. |
| 4. | There is presence of internal fragmentation and external fragmentation. | There is external fragmentation. |
| 5. | Degree of multi-programming is less. | Degree of multi-programming is higher. |
| 6. | It is more easier to implement. | It is less easier to implement. |
| 7. | There is limitation on size of process. | There is no limitation on size of process. |
Security
Security grants access to specific users of the system only.
There are external security threats associated with the system.
Convoluted queries are handled by security systems.
Security uses mechanisms like encryption and authentication (also known as certification) are used.
Protection
It deals with the access to certain system resources.
There are internal threats associated with protection of the system.
Simple queries are handled in protection.
It tries to determine the files that could be accessed or permeated by a special user.
It implements authorization mechanism.
As processes are loaded and removed from memory, the free memory space is broken into little pieces. It happens after sometimes that processes cannot be allocated to memory blocks considering their small size and memory blocks remains unused. This problem is known as Fragmentation.
Internal Fragmentation
Memory block assigned to process is bigger. Some portion of memory is left unused, as it cannot be used by another process. The internal fragmentation can be reduced by effectively assigning the smallest partition but large enough for the process.
External Fragmentation
Total memory space is enough to satisfy a request or to reside a process in it, but it is not contiguous, so it cannot be used. External fragmentation can be reduced by compaction or shuffle memory contents to place all free memory together in one large block. To make compaction feasible, relocation should be dynamic.
Following are the important differences between Internal Fragmentation and External Fragmentation.
| S.NO | Internal Fragmentation | External Fragmentation |
| 1. | If the process is larger than the memory, then internal fragmentation occurs. | If the process is removed, then external fragmentation occurs. |
| 2. | Fixed-sized memory blocks are designated for internal fragmentation. | Variable-sized memory blocks are designated for external fragmentation. |
| 3. | Internal fragmentation happens when memory is split into fixed-sized distributions. | External fragmentation happens when memory is split into variable size distributions. |
| 4. | The best-fit block is the solution to internal fragmentation. | Paging, compaction, and segmentation are solutions to external fragmentation. |
An example of a process virtual machine is the Java Virtual Machine (JVM) which allows any system to run Java applications as if they were native to the system.
Q.5 (b) Compare virtual machine and non virtual machine.
- VM is piece of software that allows you to install other software inside of it so you basically control it virtually as opposed to installing the software directly on the computer.
- Applications running on VM system can run different OS.
- VM virtualizes the computer system.
- VM size is very large.
- VM takes minutes to run, due to large size.
- VM uses a lot of system memory.
- VM is more secure.
- VM’s are useful when we require all of OS resources to run various applications.
- Examples of VM are: KVM, Xen, VMware.
- A container is a software that allows different functionalities of an application independently.
- Applications running in a container environment share a single OS.
- Containers virtualize the operating system only.
- The size of container is very light; i.e. a few megabytes.
- Containers take a few seconds to run.
- Containers require very less memory.
- Containers are less secure.
- Containers are useful when we are required to maximise the running applications using minimal servers.
- Examples of containers are:RancherOS, PhotonOS, Containers by Docker.
- Monolithic Kernel
- Hybrid kernels
- Exo kernels
- Micro kernels
The time required to read or write a disk block is determined by three factors:
- Seek time (the time to move the arm to the proper cylinder).
- Rotational delay (the time for the proper sector to rotate under the head).
- Actual data transfer time.
For most disks, the seek time dominates the other two times, so reducing the mean seek time can improve system performance substantially.
Various types of disk arm scheduling algorithms are available to decrease mean seek time.
- FCSC (First come first serve)
- SSTF (Shorted seek time first)
- SCAN
- C-SCAN
- LOOK (Elevator)
- C-LOOK